Machine Learning Visualized#
Book of Jupyter Notebooks that implement and mathematically derive machine learning algorithms from first-principles. The output of each notebook is a visualization of the machine learning algorithm throughout its training phase, ultimately converging at its optimal weights. Happy Learning! – Gavin


Chapter 4. Neural Networks#
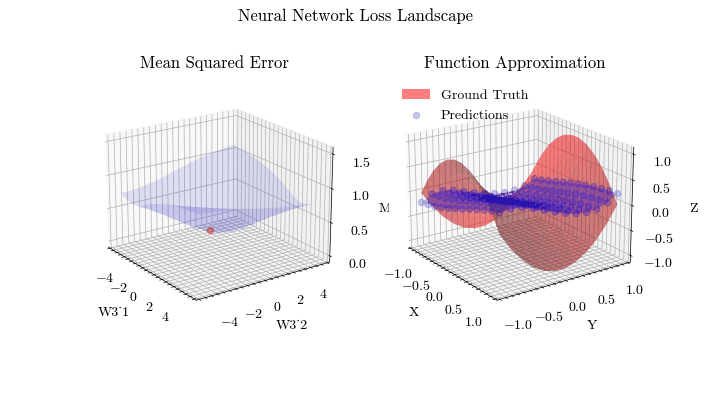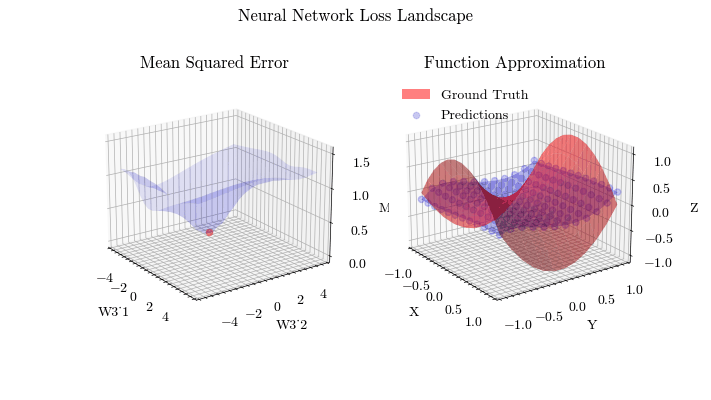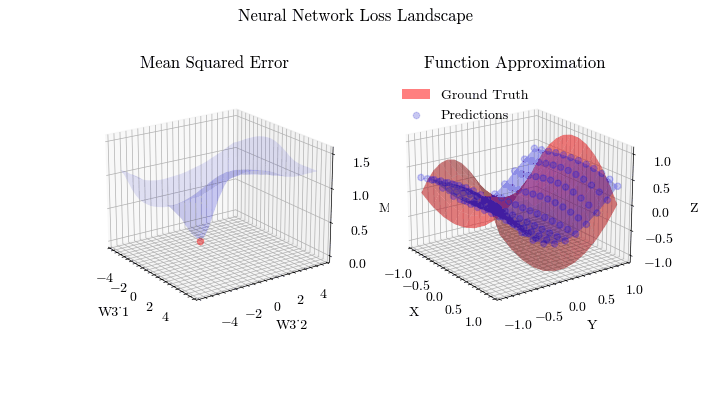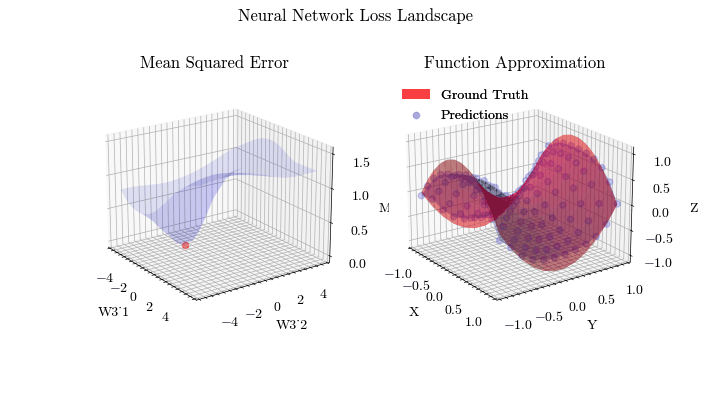
Extending on linear models, multiple layers will be stacked and new activation functions, besides sigmoid, will be applied, allowing neural networks to learn non-linear, complex functions. The optimization process of finding the optimal weights and biases on a neural network is called Backpropagation.
Neural Network Loss Landscape
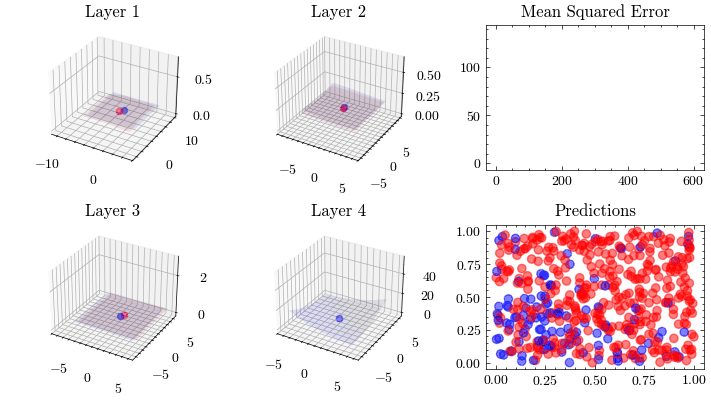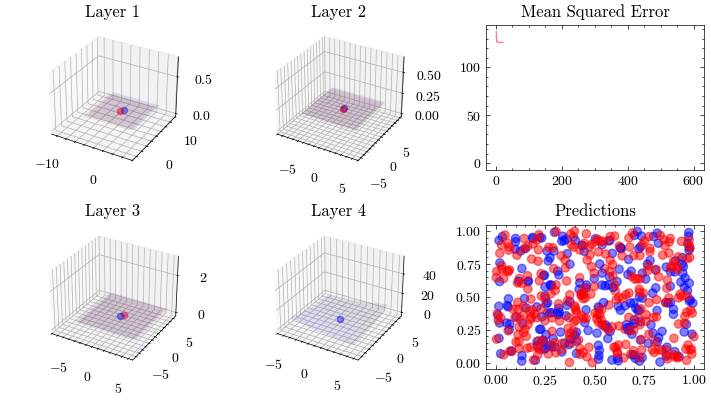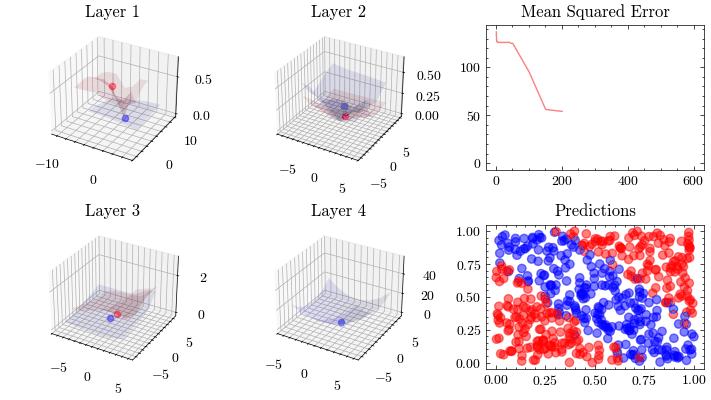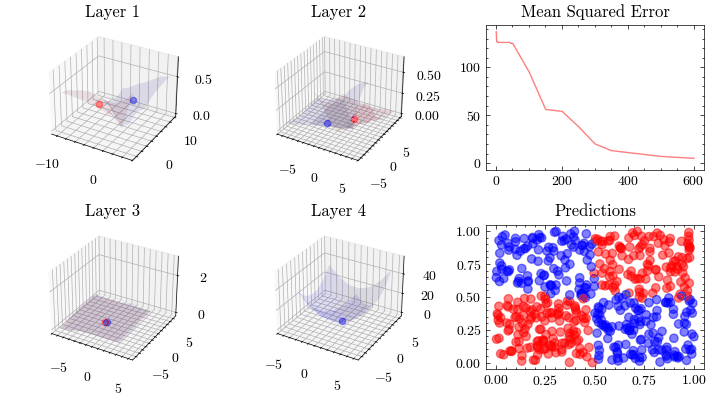
Neural Network Transformations
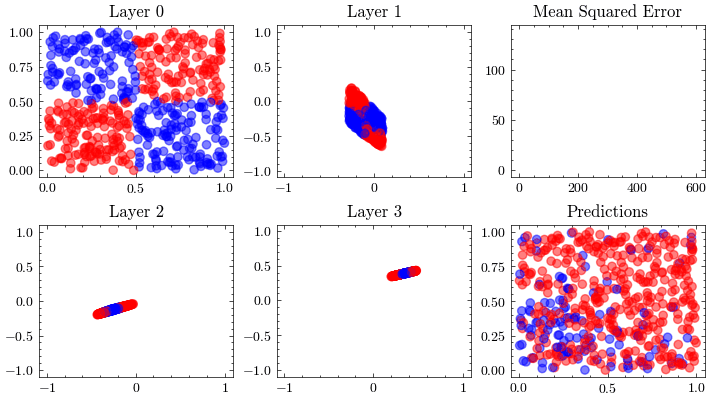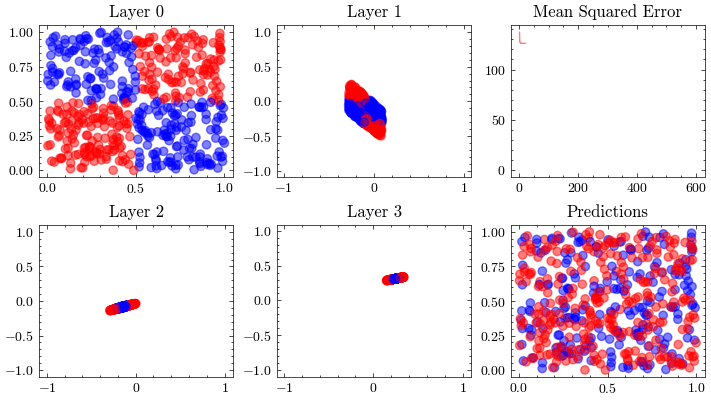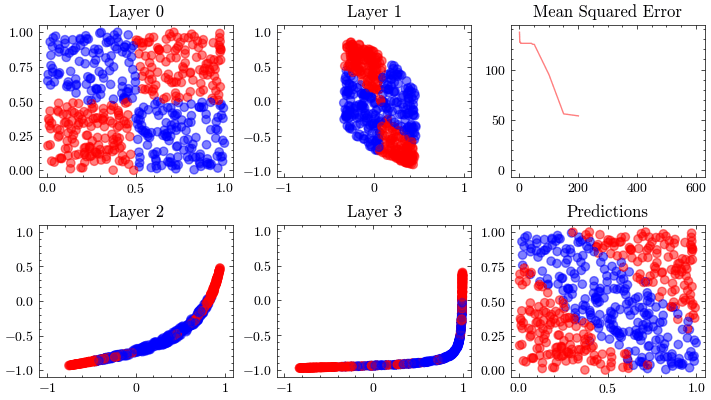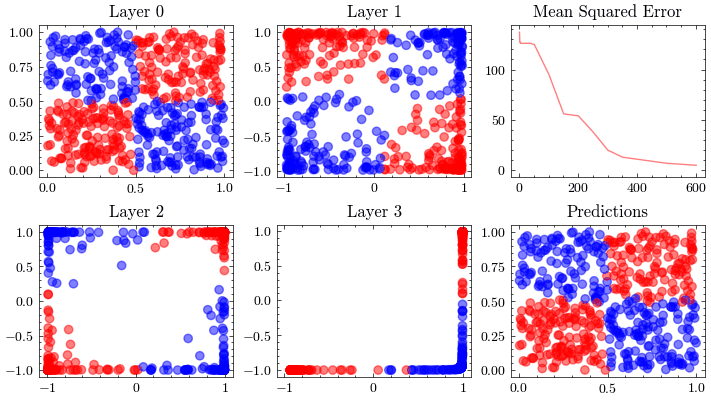
Neural Network Function Approximation
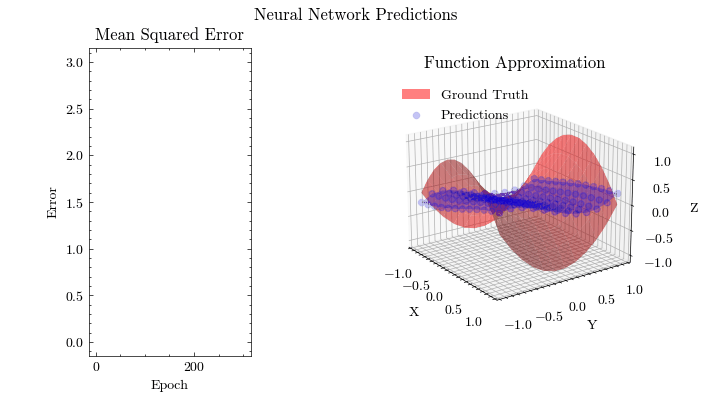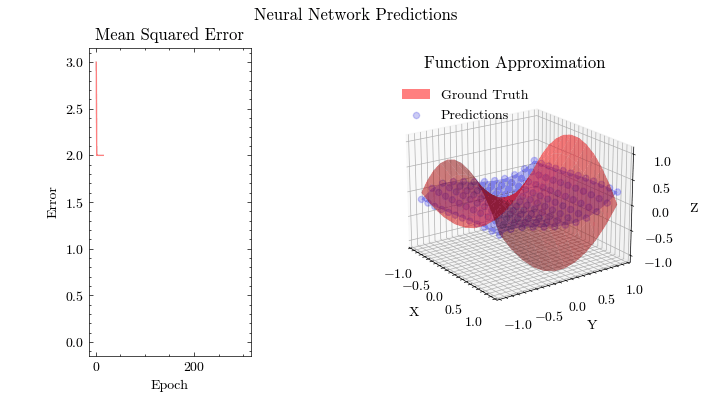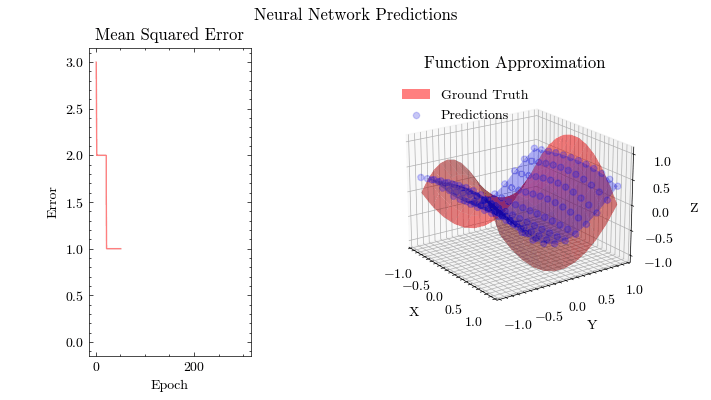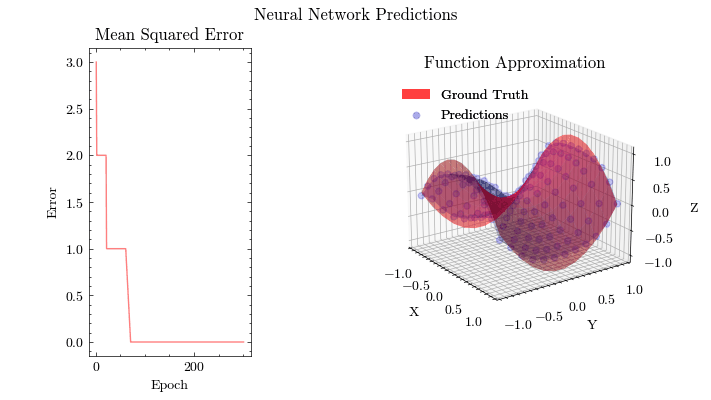
Neural Network Backpropagation
Chapter 3. Linear Models and Activation Function#
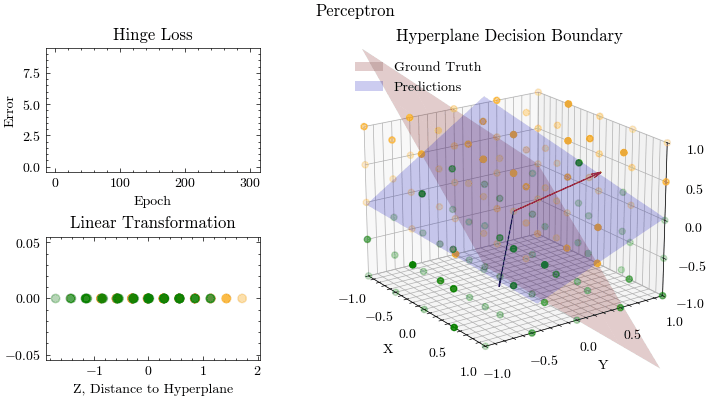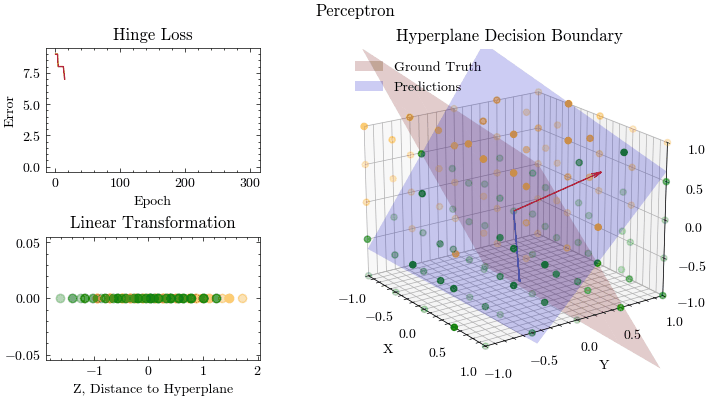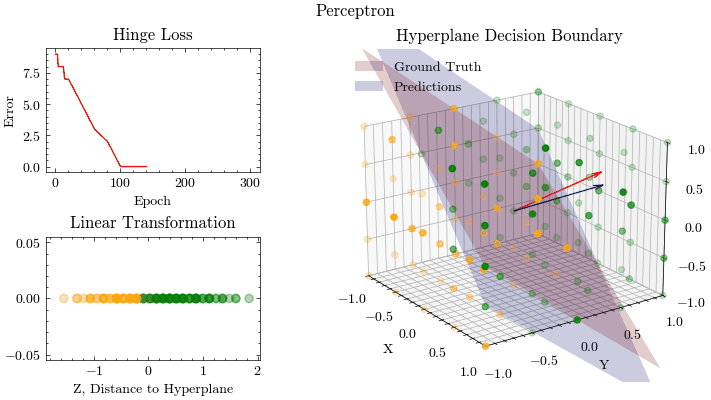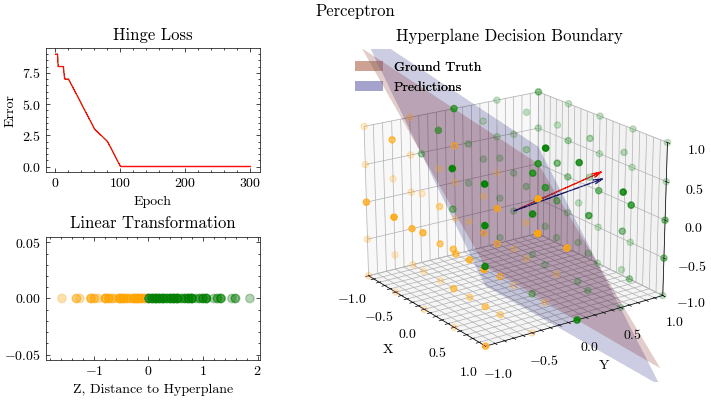
Linear models, like Perceptrons, predict outcomes by applying a linear combination on the input features. The parameters from the applied linear combination are learned from optimization algorithms, like gradient descent. This is a singe-layer neural network without an activation function. Logistic Regression extends the idea of a perceptron by introducing an activation function, called Sigmoid, and the binary cross entropy loss function.
Logistic Regression
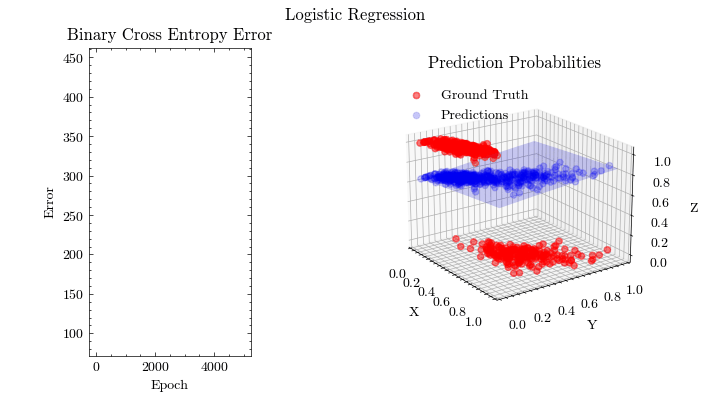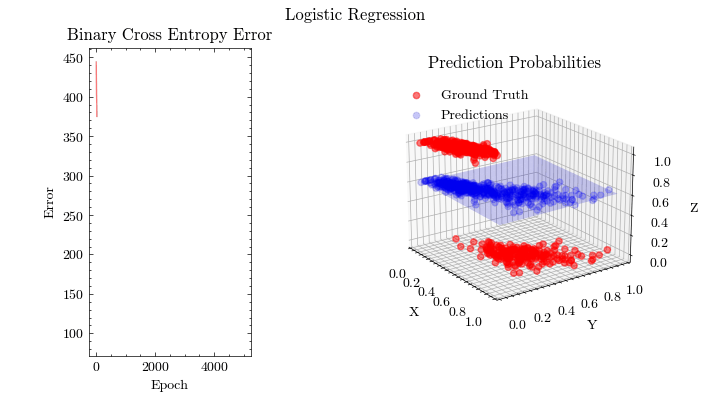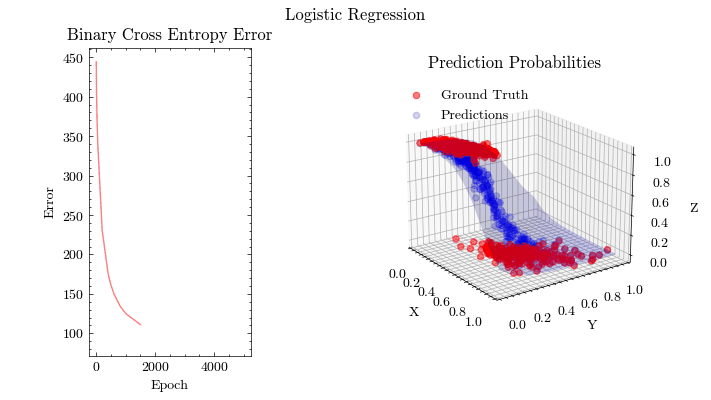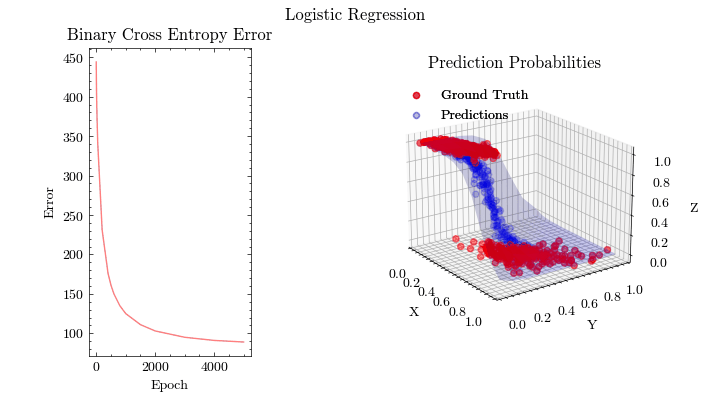
Perceptron
Chapter 2. Clustering and Reduction#
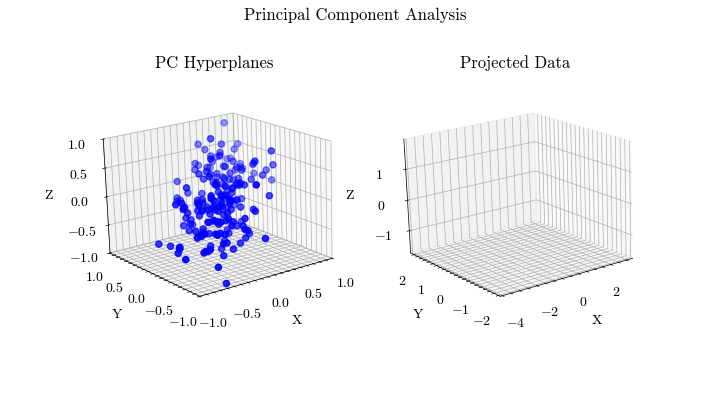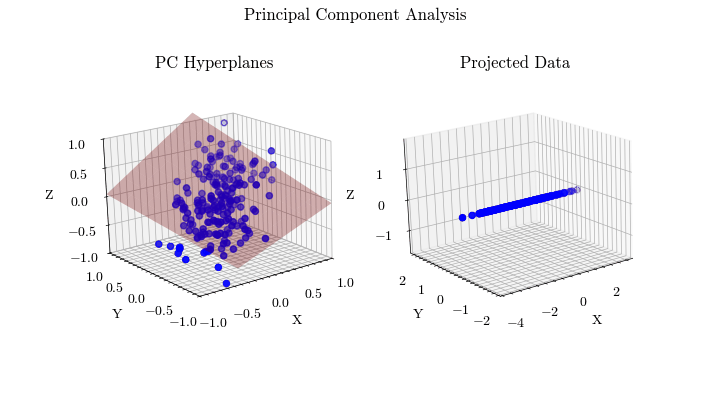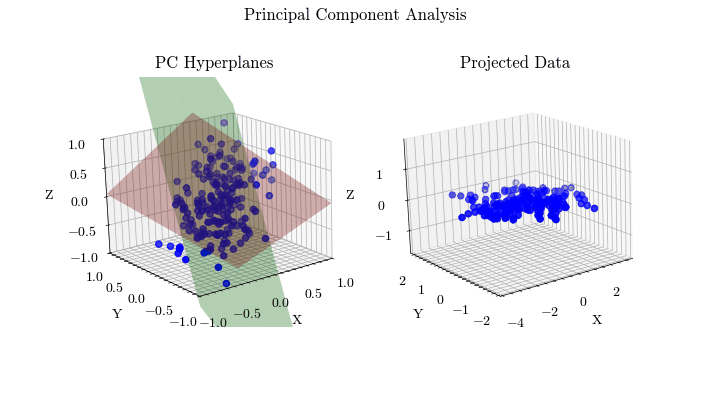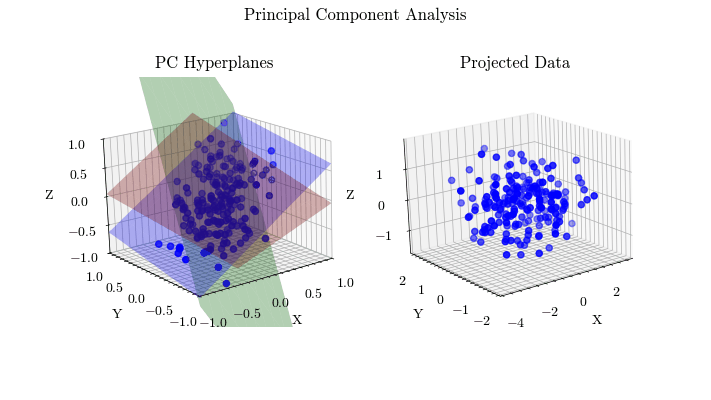
Given that machine learning models learn parameters from training data, it is important to conduct analysis on your data. Principal Component Analysis is a method of compressing your data and finding the features that account for most of the variance, allowing you to focus training on those inputs. K-Means if an unsupervised clustering algorithm that allows you to find groups of related data points, which is important for data preprocessing and identifying outliers.
K-Means Clustering
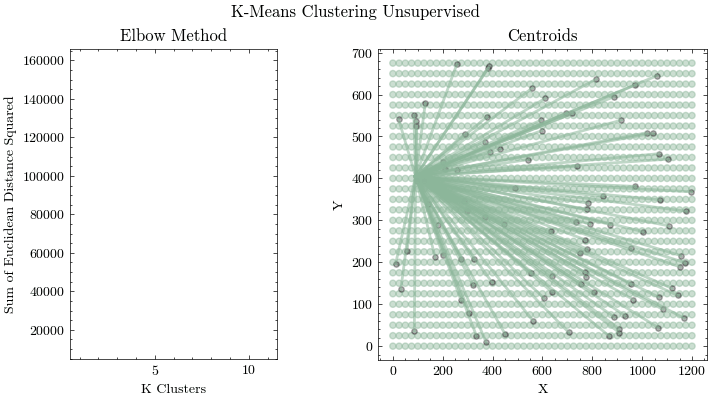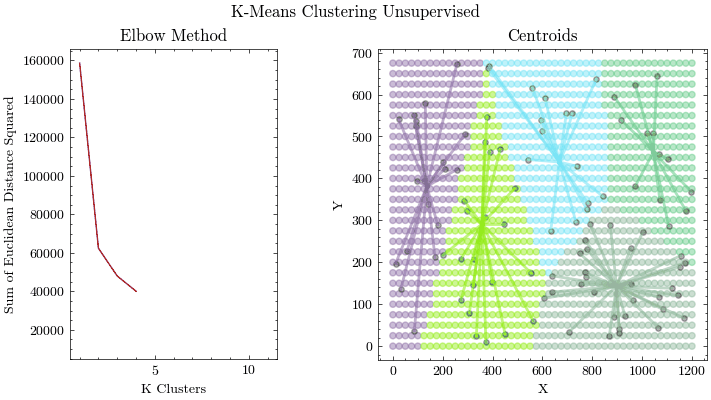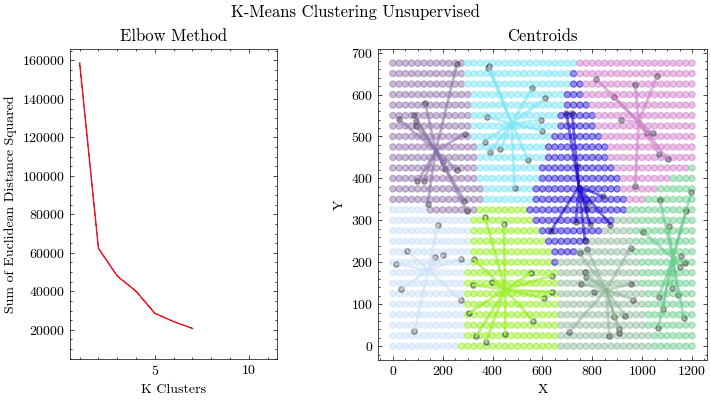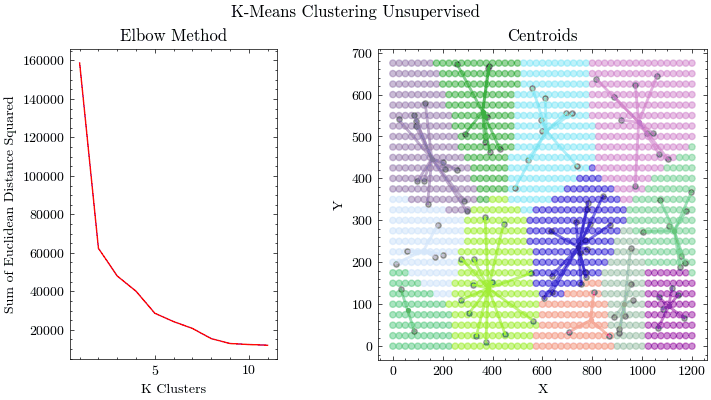
Principal Component Analysis
Chapter 1. Optimization#
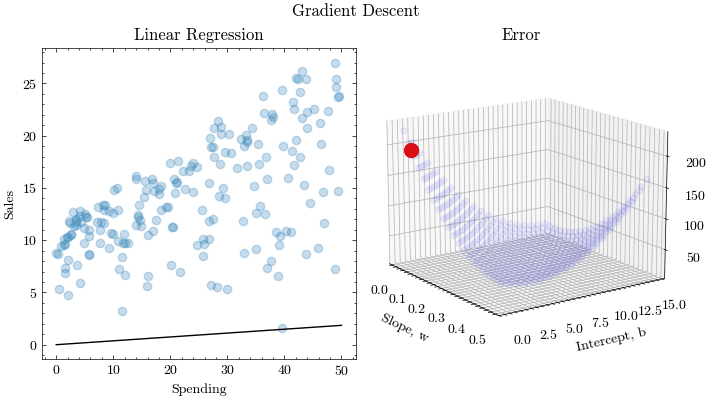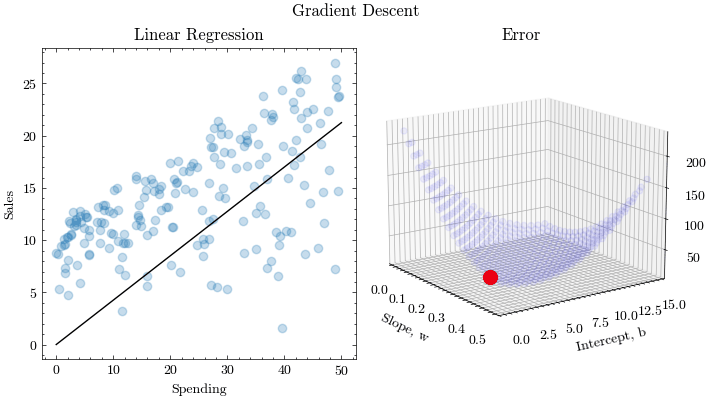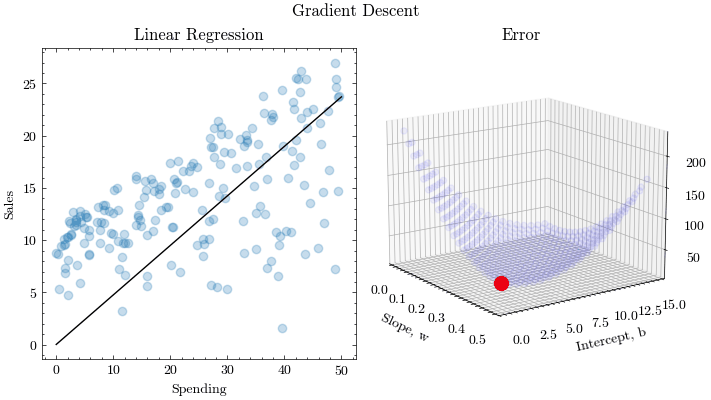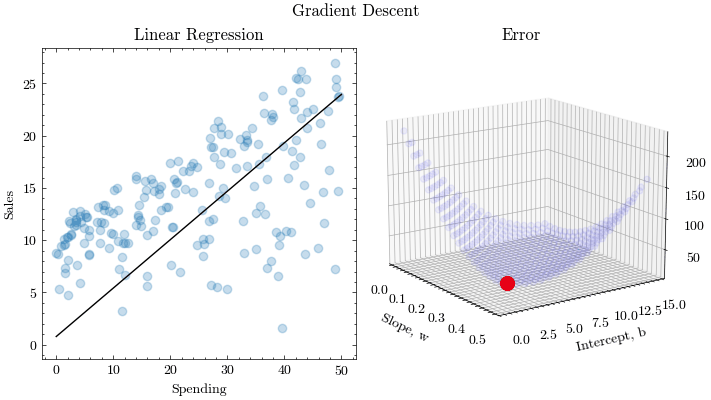
This is the process of finding the optimal input parameters that minimize the values of a function. Extending this idea to machine learning, optimization algorithms need to find the best weights and biases that yield the lowest misprediction on the loss function. Gradient Descent is one such optimization algorithm. Convergence and stability is crucial to learn the parameters.
Gradient Descent
Contributing#
I would love to create a community where people worldwide can add onto to this open-source resource/book. At a very high level, this is just a collection of Jupyter Notebooks that implement a machine learning algorithm.
If you have a Jupyter Notebook that you want to add to this book, feel free to make a pull request to the GitHub Repository. This is a reference commit showing all of the necessary code changes.
Note: You need to upload your Notebook to your own GitHub repository. Assuming you follow the reference commit, the build process for this Jupyter Book will simply download your .ipynb file and update the GitHub Pages after the pull request is approved.
About the Book#
I am a curious learner and am interested in high performance computing systems, especially supporting machine learning workloads. I plan on applying to Computer Science Graduate Programs (Master’s Degrees) and pursuing the degree part-time without interrupting my career. If you have any tips or know any contacts about computer science graduate program applications, feel free to reach out to me (ghung AT umd DOT edu).
I coded these Python Jupyter Notebooks using my lecture notes from classes at the University of Maryland, College Park.
If you want to run these Jupyter Notebooks yourself, click the download icon at the top right of any page and select the .ipynb option. Then, open and run the code blocks locally or on the cloud, like Google Colab.
For more advanced users, I made Terraform scripts to quickly spin up AWS SageMaker Notebooks here.
Notable UMD Coursework#
Machine Learning Lecture Notes#
Chapter 1:
Chapter 2:
Chapter 3:
Chapter 4: